这里写目录标题
- 前言
- 一、Nova概述
- 1.1 nova定义
- 1.2、系统架构图介绍
- 二、nova内部组件的介绍
- 2.1、nova-api
- 2.2、Scheduler
- 2.2.1 调度器的类型
- 2.2.2 过滤器类型
- 2.3、Nova-compute
- 2.4、Rabbitmq
- 2.5、Nova-conductor
- 三、Nova的工作流程
前言
nova和swift是openstack最早的两个组件,nova分为控制节点和计算节点,计算节点通过nova computer进行虚拟机创建,通过libvirt调用kvm创建虚拟机,nova之间通信通过rabbitMQ队列进行通信
一、Nova概述
1.1 nova定义
Nova(OpenStack Compute Service)是 OpenStack 最核心的服务,负责维护和管理云环境的计算资源,同时管理虚拟机生命周期。
1.2、系统架构图介绍
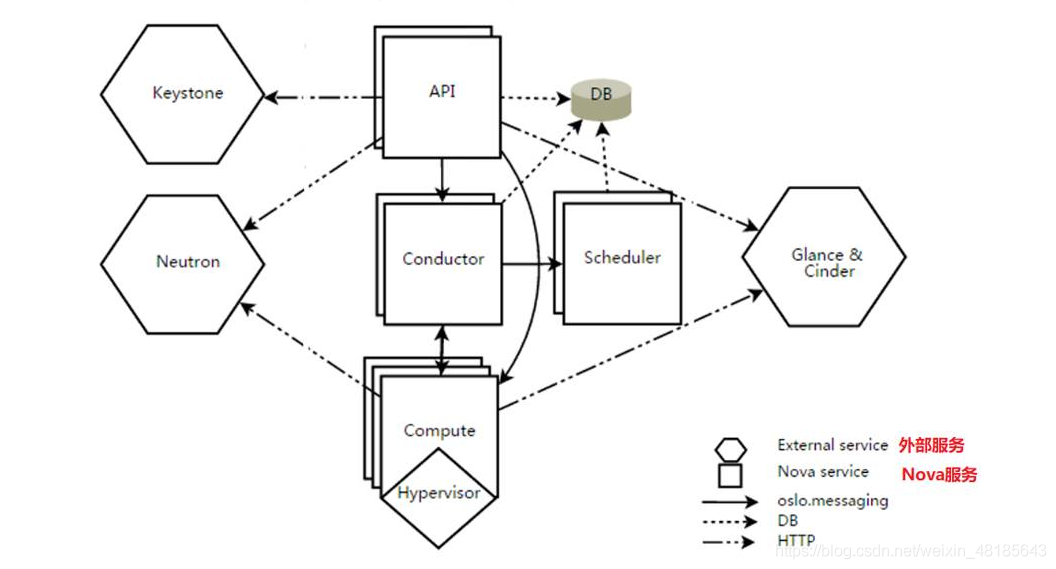
- DB:用于数据存储的sql数据库。
- API:用于接收HTTP请求、转换命令、通过消息队列或HTTP与其他组件通信的nova组件。
- Scheduler:用于决定哪台计算节点承载计算实例的nova调度器。
- Network:管理IP转发、网桥或虚拟局域网的nova网络组件。
- Compute:管理虚拟机管理器与虚拟机之间通信的nova计算组件。
- Conductor:处理需要协调(构建虚拟机或调整虚拟机大小)的请求,或者处理对象转换
二、nova内部组件的介绍
2.1、nova-api
-
AsPI是客户访问nova的http接口,它由nova-api服务实现,nova-api服务接受和响应来自最终用户计算api的请求。作为openstack对外服务的最主要接口,nova-api提供了一个集中的可以查询所有api的端点。
-
所有对nova的请求都首先由nova-api处理。API提供REST 标准调用服务,便于与第三方系统集成。
-
最终用户不会直接该送RESTful API请求而是通过openstack命令行、dashbord和其他需要跟nova的组件使用这些API。
-
NOva-api对接受到的HTTP API请求做以下处理:
(1)检查客户端传入的参数是否合法有效
(2)调用nova其他服务来处理客户端HTTP请求
(3)格式化nova其他子服务返回结果并返回给客户端 -
nova-api是外部访问并使用nova提供的各种服务的唯一途径,也是客户端和nova之间的中间层。
2.2、Scheduler
Scheduler可译为调度器,由nova-scheduler服务实现,主要解决的是如何选择在哪个计算节点上启动实例的问题。它可以应用多种规则,如果考虑内存使用率、cpu负载率、cpu架构(Intel/amd)等多种因素,根据一定的算法,确定虚拟机实例能够运行在哪一台计算节点。NOva-scherduler服务会从队列中接受虚拟机实例的请求,通过读取数据库的内容,从可用资源池中选择最合适的计算节点来创建新的虚拟机实例
2.2.1 调度器的类型
(1)随机调度器(chance scheduler):从所有正常运行nova-compute服务的节点中随机选择
(2)过滤器调度器(filter scheduler):根据指定的过滤条件以及权重选择最佳的计算节点。Filter又称为筛选器
(3) 缓存调度器(caching scheduler):可看作随机调度器的一种特殊类型,在随机调度的基础上将主机资源信息缓存在本地内存中,然后通过后台的定时任务定时从数据库中获取最新的主机资源信息
- 过滤器调度器过程
通过指定的过滤器选择满足条件的计算节点,比如内存使用小于50%,可以使用多个过滤器依次进行过滤
对过滤之后的主机进行权重计算并排序,选择最优的计算节点来创建虚拟机实例
2.2.2 过滤器类型
-
再审过滤器(RetryFilter)
主要作用是过滤掉之前已经调度过的节点(类比污点)。如A、B、C都通过了过滤,A权重最大被选中执行操作,由于某种原因,操作在A上失败了。Nova-filter 将重新执行过滤操作,再审过滤器直接过滤掉A,以免再次失败。 -
可用区域过滤器(AvailabilityZoneFilter)
主要作用是提供容灾性,并提供隔离服务,可以将计算节点划分到不同的可用区域中。Openstack默认有一个命名为nova的可用区域,所有计算节点一开始都在其中。用户可以根据需要创建自己的一个可用区域。创建实例时,需要指定将实例部署在那个可用区域中。通过可用区过滤器,将不属于指定可用区的计算节点过滤掉。 -
内存过滤器(RamFilter)
根据可用内存来调度虚拟机创建,将不能满足实例类型内存需求的计算节点过滤掉,但为了提高系统资源利用率, Openstack在计算节点的可用内存允许超过实际内存大小,可临时突破上限,超过的程度是通过nova.conf配置文件中ram_ allocation_ ratio参数来控制的, 默认值是1.5。(但这只是临时的)
Vi /etc/nova/nova . conf
Ram_ allocation_ ratio=1 .5 -
硬盘过滤器(DiskFilter)
根据磁盘空间来调度虚拟机创建,将不能满足类型磁盘需求的计算节点过滤掉。磁盘同样允许超量,超量值可修改nova.conf中disk_ allocation_ ratio参数控制,默认值是1.0,(也是临时的)
Vi /etc/nova/nova.conf
disk_ allocation_ ratio=1.0 -
核心过滤器(CoreFilter)
根据可用CPU核心来调度虚拟机创建,将不能满足实例类型vCPU需求的计算节点过滤掉。vCPU也允许超量,超量值是通过修改nova.conf中cpu_ allocation_ratio参数控制,默认值是16。
Vi /etc/nova/nova. conf
cpu_allocation_ ratio=16.0 -
计算过滤器(ComputeFilter)
保证只有nova-compute服务正常工作的计算节点才能被nova-scheduler调度,它是必选的过滤器。 -
镜像属性过滤器(ImagePropertiesFilter)
根据所选镜像的属性来筛选匹配的计算节点,通过元数据来指定其属性。如希望镜像只运行在KVM的Hypervisor上,可以通过Hypervisor Type属性来指定。 -
服务器组反亲和性过滤器
要求尽量将实例分散部署到不同的节点上,设置一个服务器组,组内的实例会通过此过滤器部署到不同的计算节点。适用于需要分开部署的实例。
服务器组亲和性过滤器
此服务器组内的实例,会通过此过滤器,被部署在同一计算节点上,适用于需要位于相同节点的实例服务。

-
调度器与DB的交互过程
scheduler组件决定的是虚拟机实例部署在哪台计算节点上并调度,在调度之前,会先向数据库获取宿主机资源信息作为依据;之后可通过过滤器和权重选择最合适的节点调度,或者指定节点直接调度;计算节点的 libvirt 工具负责收集宿主机的虚拟化资源,根据已创建的实例再次统计资源,将资源信息更新到数据库中,整个更新资源信息的过程是周期性执行的,而不是实时的,所以存在一个问题,当刚创建完一个实例,随即又需要创建时,数据库还未来得及更新宿主机的最新状态,那么调度器依据的信息就不正确,有可能所选的节点资源并不够用,而导致调度失败。这同时也是缓存调度器的缺陷,无法实时获取租主机资源信息。我们可在调度完成时,直接将资源信息返回给数据库,更新数据库状态,解决这个问题。
2.3、Nova-compute
Nova-compute处理管理实例生命周期。他们通过Message Queue接收实例生命周期管理的请求,并承担操作工作。在一个典型生产环境的云部署中有一些compute workers。一个实例部署在哪个可用的compute worker上取决于调度算法。
2.4、Rabbitmq
OpenStack 节点之间通过消息队列使用AMQP(Advanced Message Queue Protocol)完成通信。Nova 通过异步调用请求响应,使用回调函数在收到响应时触发。因为使用了异步通信,不会有用户长时间卡在等待状态。这是有效的,因为许多API调用预期的行为都非常耗时,例如加载一个实例,或者上传一个镜像。
2.5、Nova-conductor
nova-conductor是nova-compute与数据库的中间件,nova-compute对数据库的CRUD操作都借由nova-conductor完成,nova-conductor通过rpc对外提供API服务。nova-conductor默认采用多进程运行,在不配置[conductor]worker的情况下,进程数会与服务器的逻辑CPU数一致。
三、Nova的工作流程
- 其他组件需要nova调用资源时,会先去keystone组件那拿到token令牌,然后拿着令牌给nova-api看,nova-api也要拿着token令牌去找keystone验证,验证成功后,nova内部的组件就开始各司其职了
- nova-api要找到相应的组件来干活,之前外部所需要的资源信息就放入DB数据库中,然后通过消息队列来告诉nova-scheduler,让它来安排一下
- 接着nova-scheduler通过自己的一系列调度算法(例如内存使用率,cpu负载率,,cpu架构等)来确定在那台计算节点上运行,看到DB数据库中所需要的资源信息,通过自己的调度算法,给nova-compute交代任务。
- 因为nova-compute的处于云主机上,安全性不高,所以nova-compute不知道DB数据库在哪,然后nova-compute就让nova-conductor去DB查看来告诉自己相关消息。
- 最后nova-compute看到DB数据库的信息,就拿着token令牌去其他openstack组件拿相应资源,(例如,glance镜像服务,cinder磁盘空间等)



